I have been working to build a new router for a customer and have had access to a pair of Spirent SmartBits SMB-600 with gigabit interfaces. This gave me the opportunity to do some testing. The machines available are Dell PowerEdge 860's with "80557,Xeon 3000 Conroe,3060,LGA775,Burn 2" processors. I tested with the onboard bge interfaces and thanks to Dave some em NICs as well.
If you have any questions or comments, You can send me email at andrew AT afresh1.com or find me on Twitter
I tested with amd64 and i386 under both single and multiprocessor kernels. I had two identical PE860s, one running amd64 and one running i386. Here are a few of the important dmesg bits.
cpu0: Intel(R) Xeon(R) CPU 3060 @ 2.40GHz, 2400.41 MHz
cpu0: FPU,VME,DE,PSE,TSC,MSR,PAE,MCE,CX8,APIC,SEP,MTRR,PGE,MCA,CMOV,PAT,
PSE36,CFLUSH,DS,ACPI,MMX,FXSR,SSE,SSE2,SS,HTT,TM,SBF,SSE3,MWAIT,
DS-CPL,VMX,EST,TM2,SSSE3,CX16,xTPR,PDCM,NXE,LONG
cpu0: 4MB 64b/line 16-way L2 cache
cpu0: apic clock running at 266MHz
bge0 at pci4 dev 0 function 0 "Broadcom BCM5721" rev 0x11, BCM5750 B1 (0x4101):
apic 2 int 16 (irq 5), address 00:18:8b:f9:57:b4
brgphy0 at bge0 phy 1: BCM5750 10/100/1000baseT PHY, rev. 0
em0 at pci3 dev 0 function 0 "Intel PRO/1000 PT (82571EB)" rev 0x06:
apic 2 int 16 (irq 5), address 00:15:17:7d:89:ce
The test setup was 10 identical TCP flows in a single direction. The SmartFlow application I was using does not set up TCP connections so there were no states created although PF was running with the default ruleset. The connections were fairly straight forward, Spirent port 1 to Cisco 4948 to router interface and back through the Cisco to Spirent port 2. I would move the hostname.if between hostname.bge0 and hostname.em0 and reboot.
# hostname.if
inet 10.1.1.1 255.255.255.0
inet alias 10.1.2.1 255.255.255.0
The only tuning change I made was to increase the sysctl net.inet.ip.ifq.maxlen to 1024 from the default of 256 which stopped net.inet.ip.ifq.drops from incrementing.
Full results are available here, see the "full" subdirectory for the results in csv format.
- AMD64/bsd.mp/bge/
- AMD64/bsd.mp/em/
- AMD64/bsd.sp/bge/
- AMD64/bsd.sp/em/
- i386/bsd.mp/bge/
- i386/bsd.mp/em-no_ppb/
- i386/bsd.mp/em/
- i386/bsd.sp/bge/
- i386/bsd.sp/em-no_ppb/
- i386/bsd.sp/em/
- i386/bsd.sp/em1/
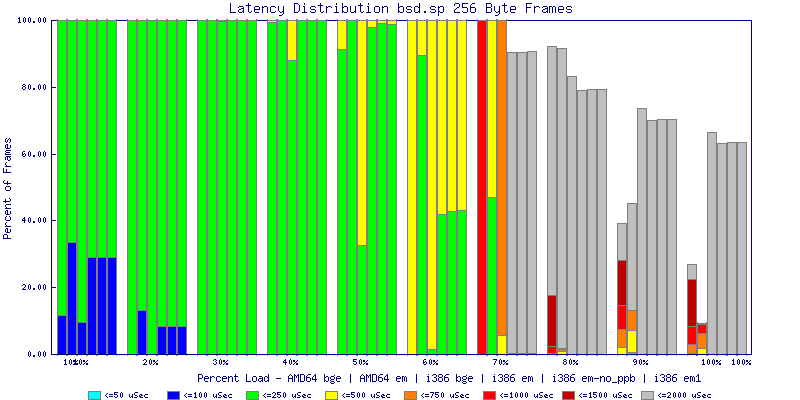
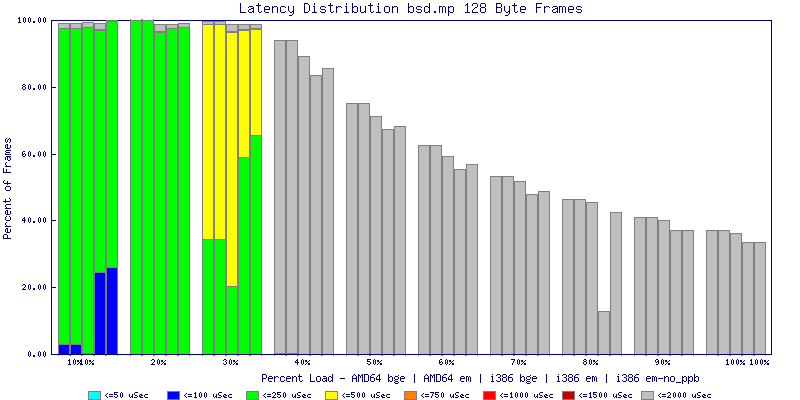
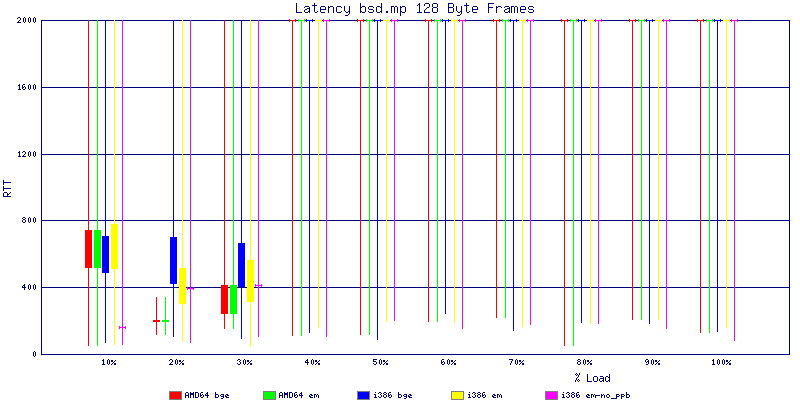
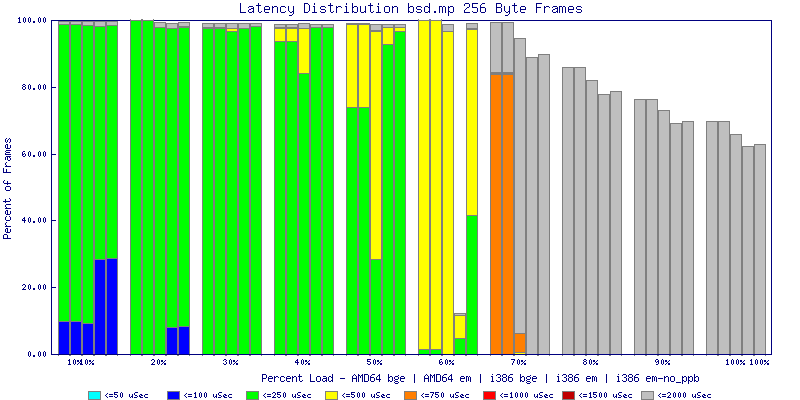
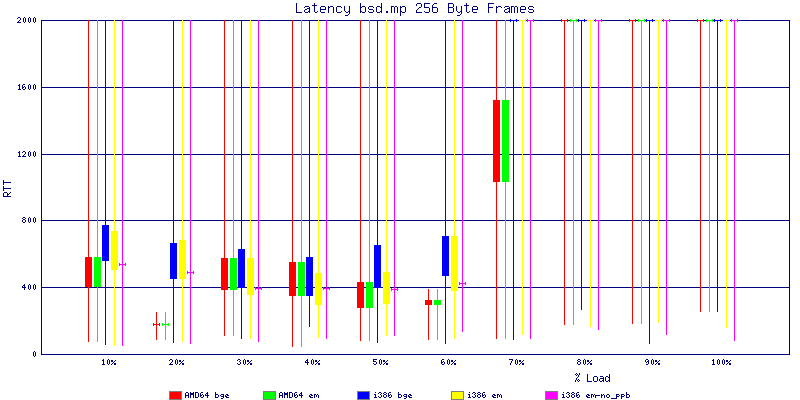
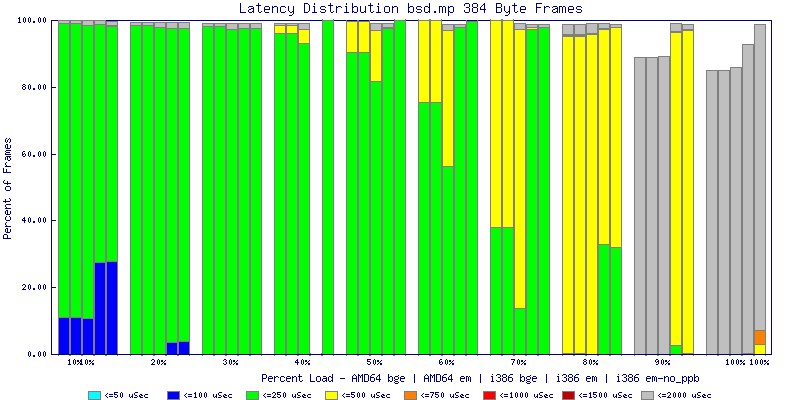
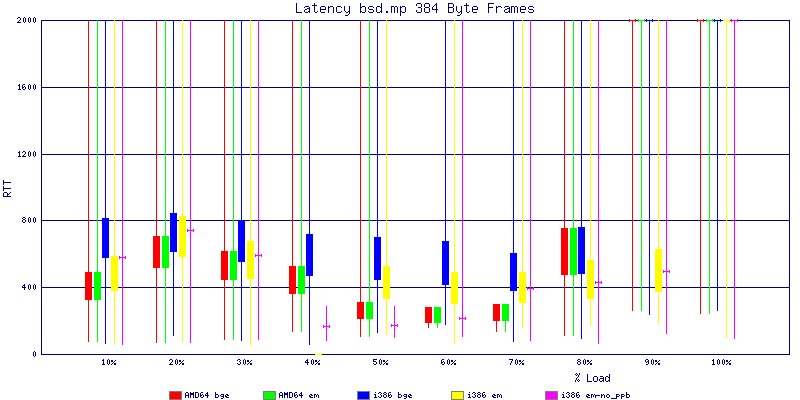
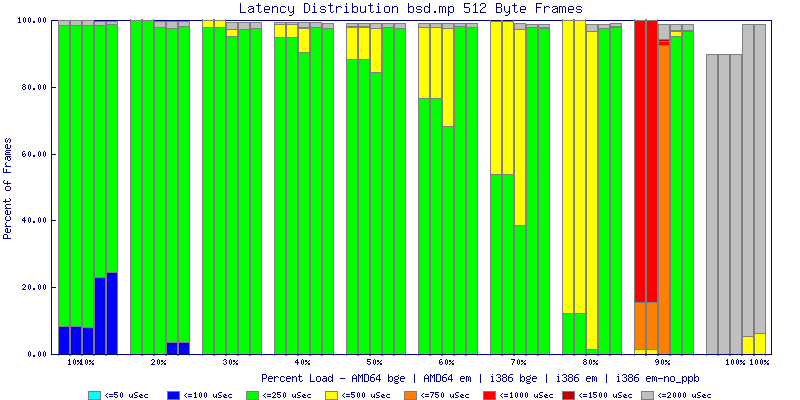
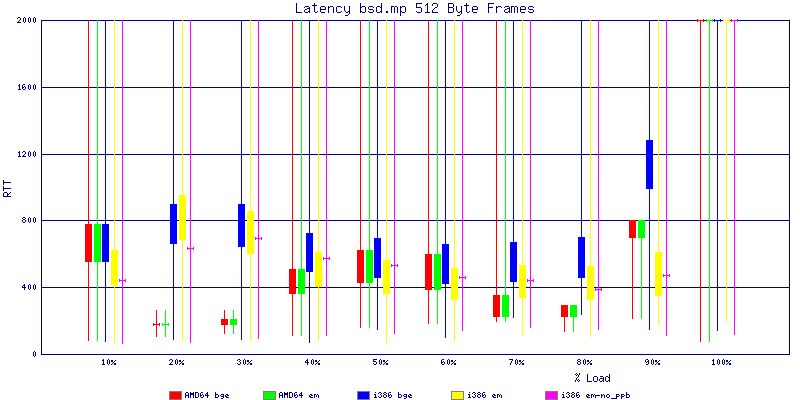
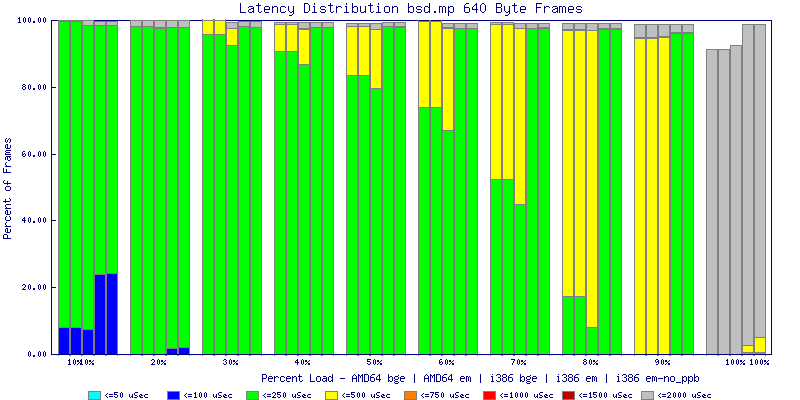
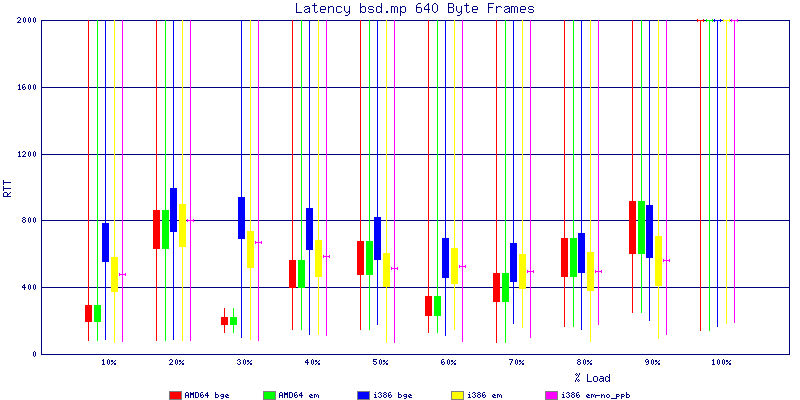
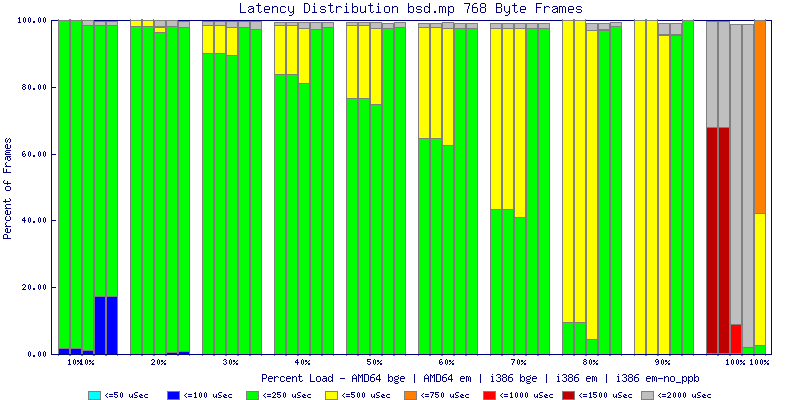
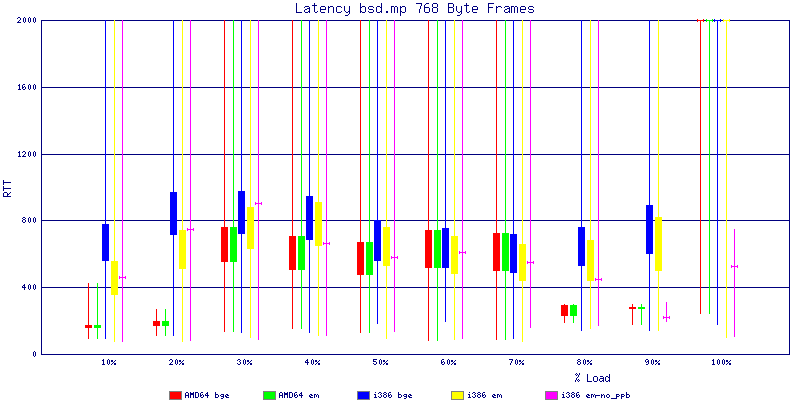
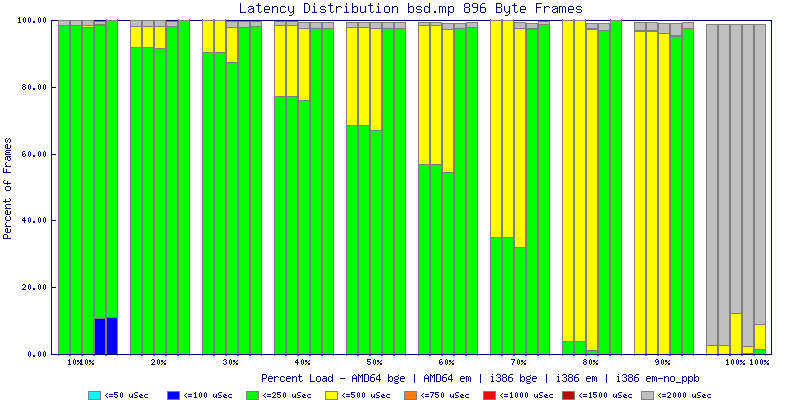
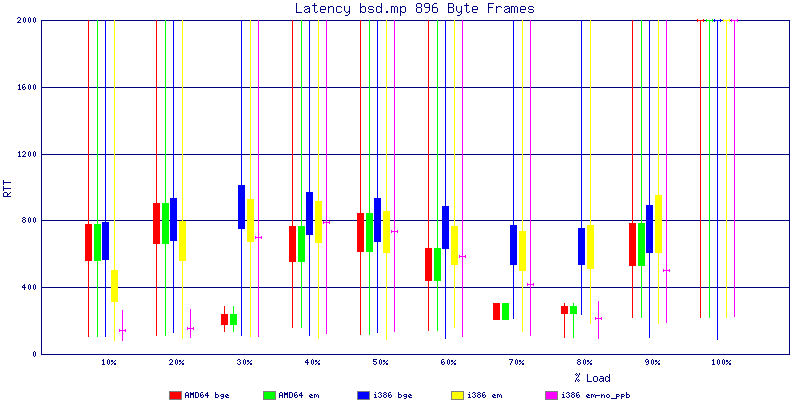
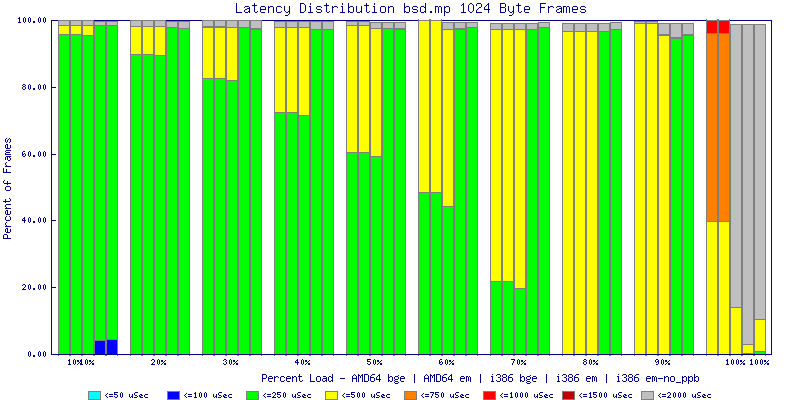
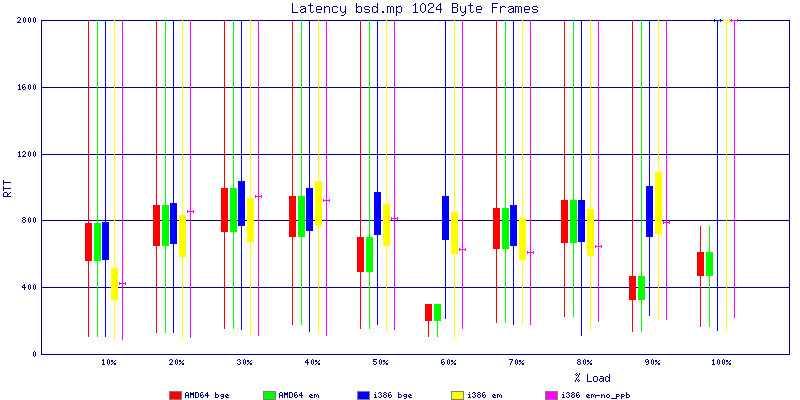
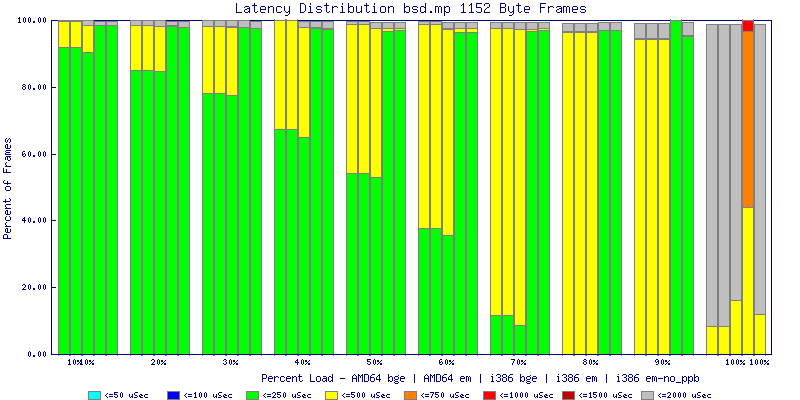
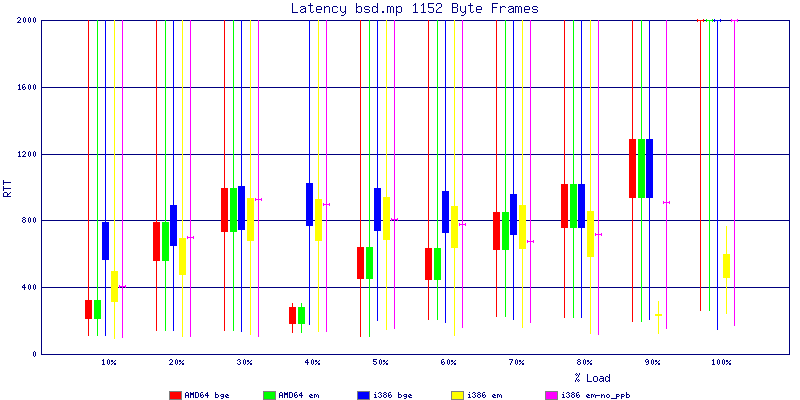
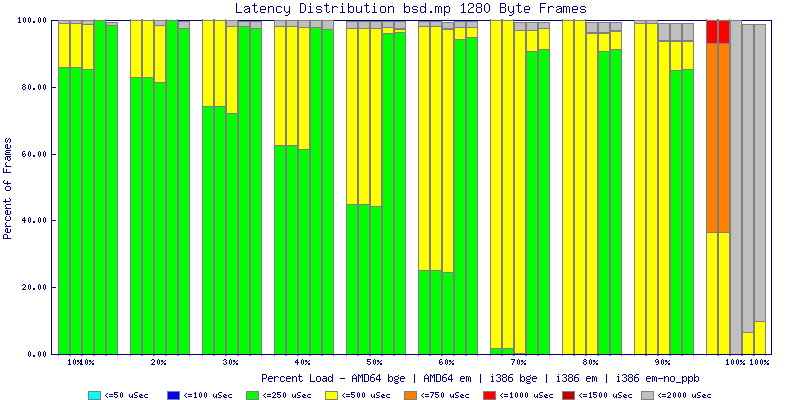
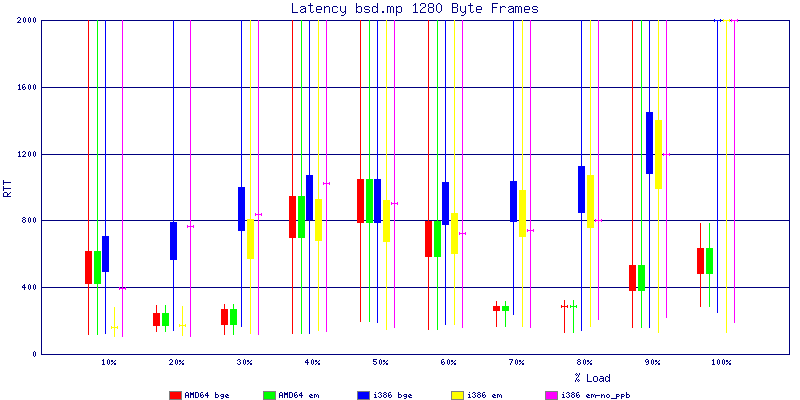
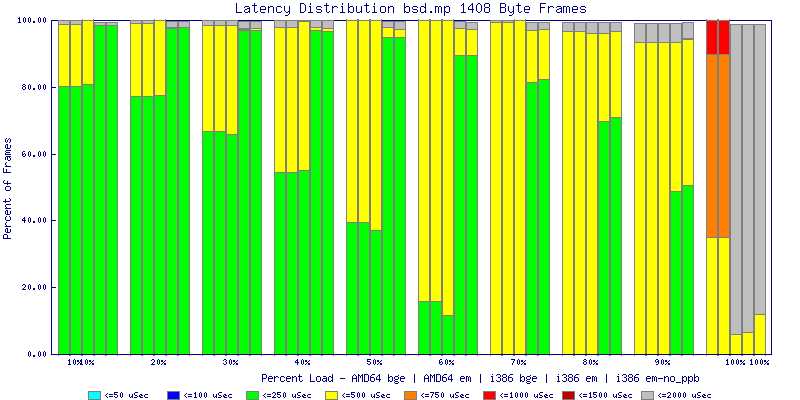
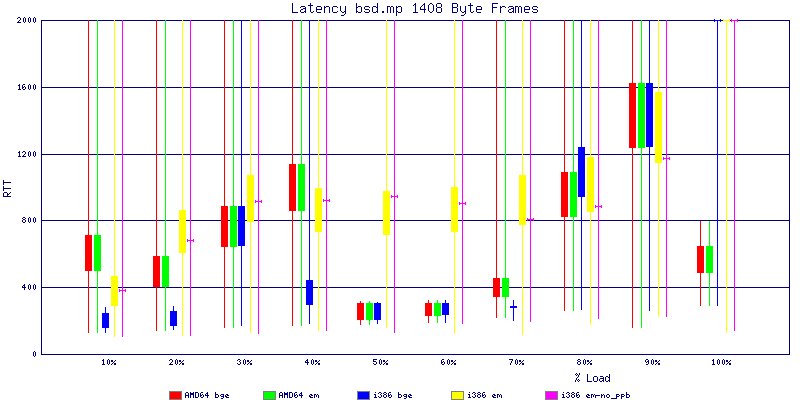
My summarized results, generated from scripts I wrote are available in Throughput.csv, Latency.csv and Frame_Loss.csv. I didn't generate any graphs from Frame_Loss.csv, but you can see the loss in the Latency Distribution graphs.
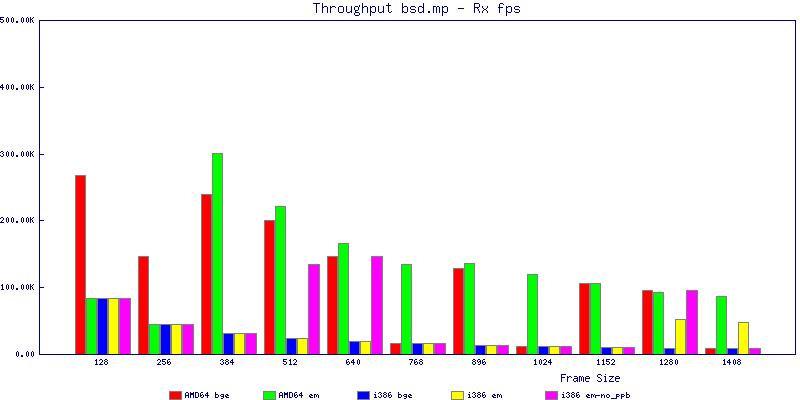
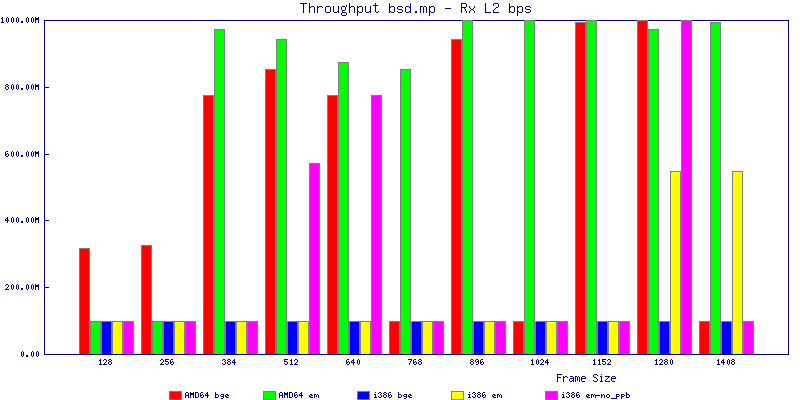
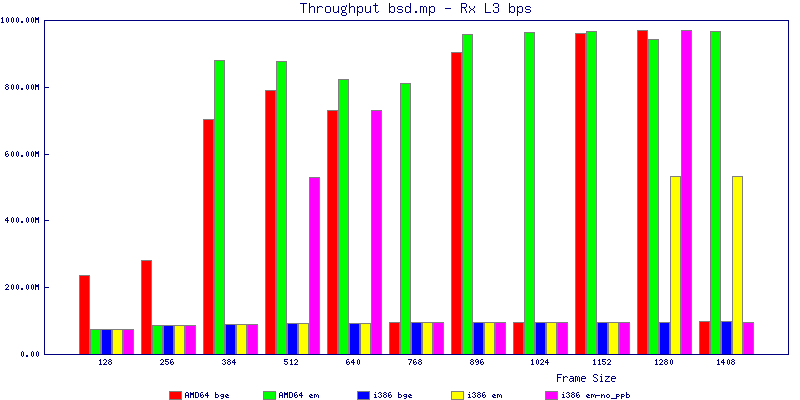
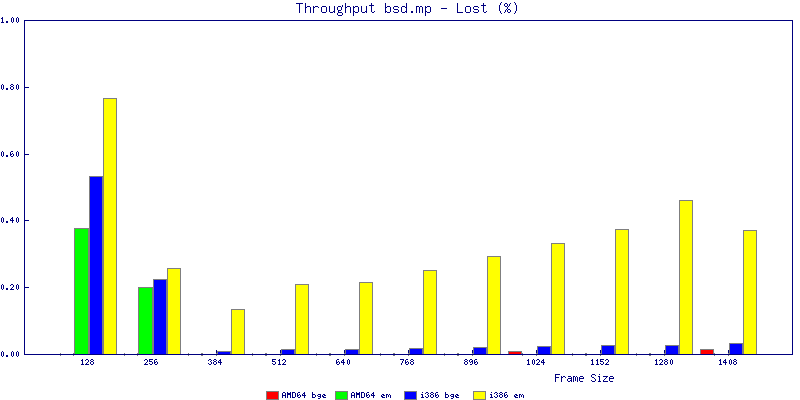
The bsd.mp graphs are at the bottom of the page, the reason for this is I would get input errors regularly every 5 seconds while running bsd.mp either i386 or amd64 and with both network cards. Those input errors seemed to correlate with packet loss. It happened with any size packets and on any amount of load. I was never able to track it down, but do recommend (as is generally recommended on the lists) using a single processor kernel on your OpenBSD router.
NOTE: These graphs are based on 1Gbps traffic, so when you see 10% load, that is 100Mbps of traffic.
I had a request to test a patch disabling the ppm hotplug interrupt which was shared with bge0 and em0 and they provided pre-built kernels with the patch applied so I ran the tests. While looking, I noticed that em1 was also not sharing that interrupt so I ran the tests on em1 as well. The results indicated that it helped a little bit. In that test, i386 bsd.sp em1 got 310124 instead of 298247 on em0 at 128 byte packets and at 256 bytes em1 got 303230 fps instead of em0 296861 fps.
$ vmstat -iz
interrupt total rate
irq0/clock 7554468 99
irq131/acpi0 0 0
irq81/mpi0 27212 0
irq81/em0 49698267 655
irq96/em1 0 0
irq81/bge0 0 0
irq96/bge1 150345 1
irq82/uhci0 0 0
irq83/uhci1 0 0
irq84/uhci2 0 0
irq82/ehci0 17 0
irq80/pciide0 0 0
irq130/com0 0 0
irq129/pckbc0 0 0
Total 57430309 757
The bsd.sp throughput graphs show that for any average packet size above 767 bytes you can saturate a gigabit network interface with packet forwarding easily. I was able to achieve close to 300k pps with any configuration I tested. Surprisingly with small packet sizes, amd64 did slightly better than i386 achieving a maximum of of 347,812 pps with the em NIC.
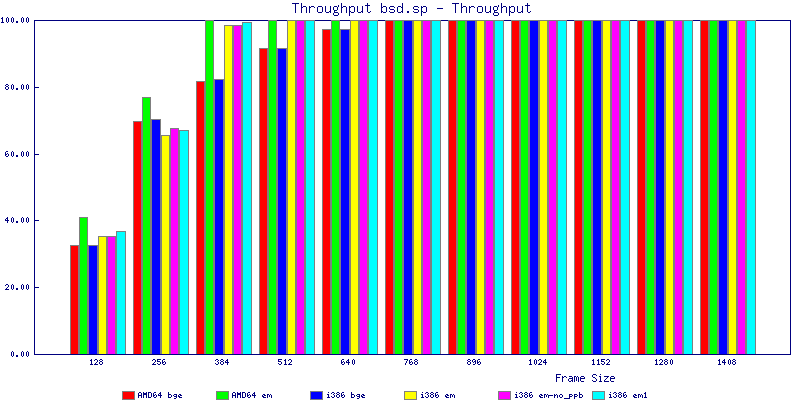
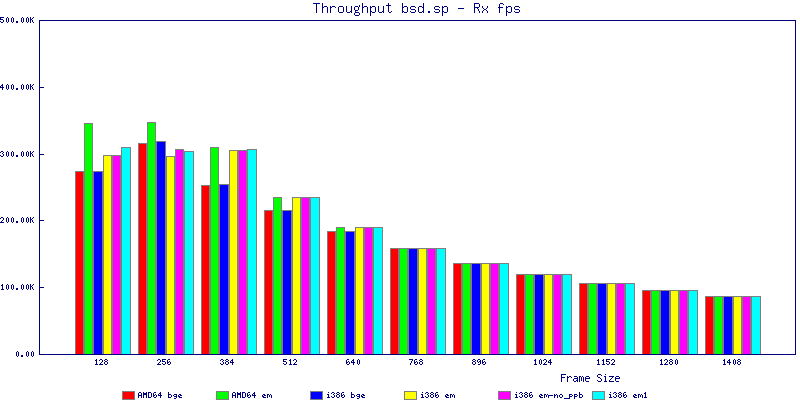
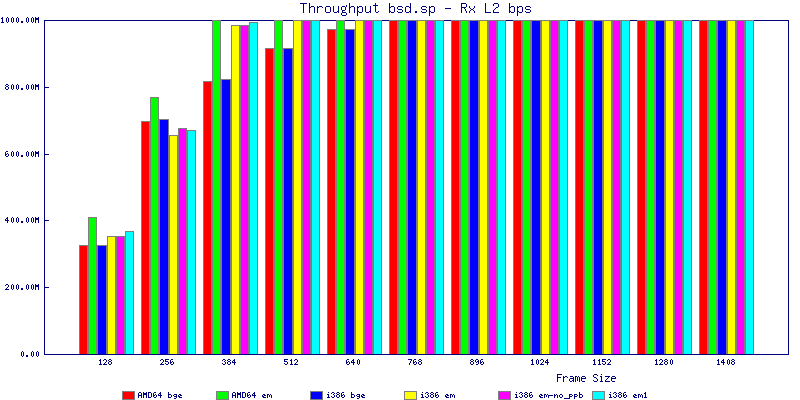
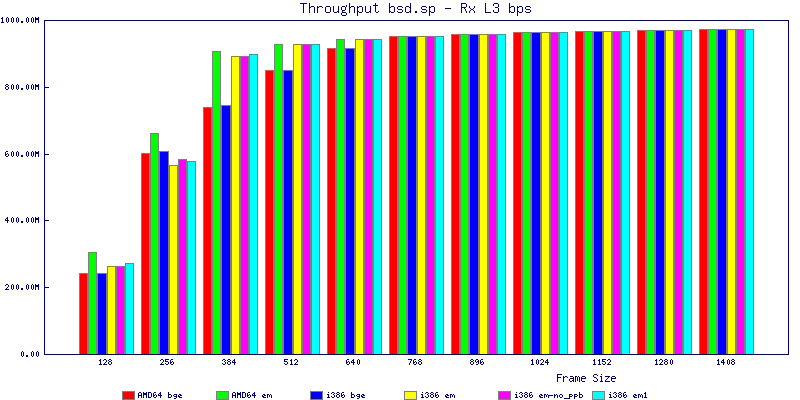
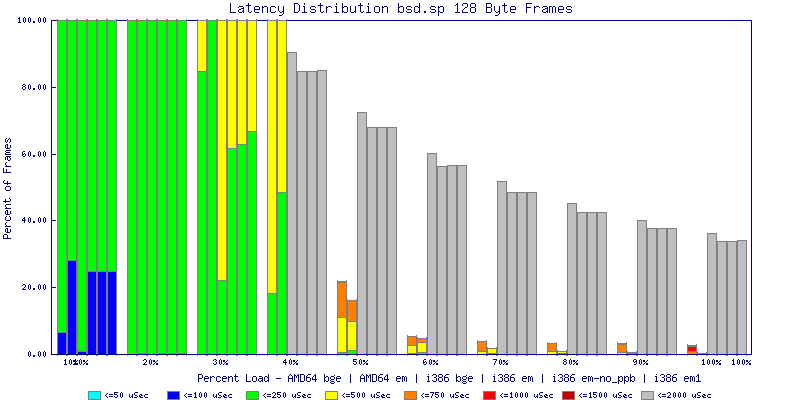
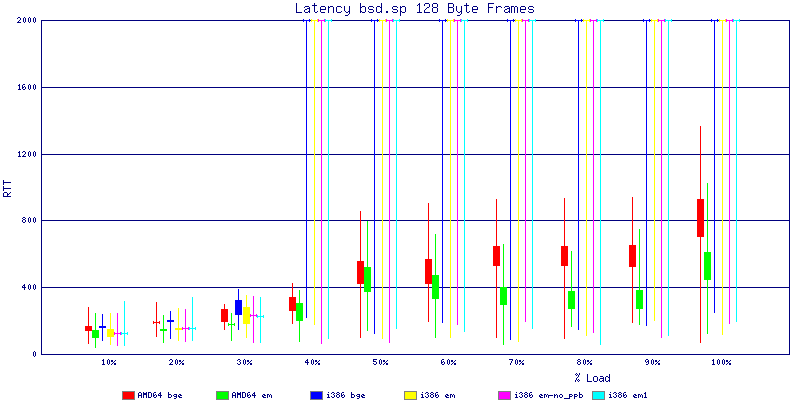
The latency graphs show that at high packet rates the em nics have lower latency. Do notice that these times are in microseconds so thousandths of a millisecond. I trimmed the latency graphs at 2000 microseconds because at 100% load the latency was effected. This means, try not to overload your network.
The em interface had reliably lower latency, but perhaps not significantly and while i386 did pass more packets at higher packet rates, the packets that amd64 passed had lower latency.
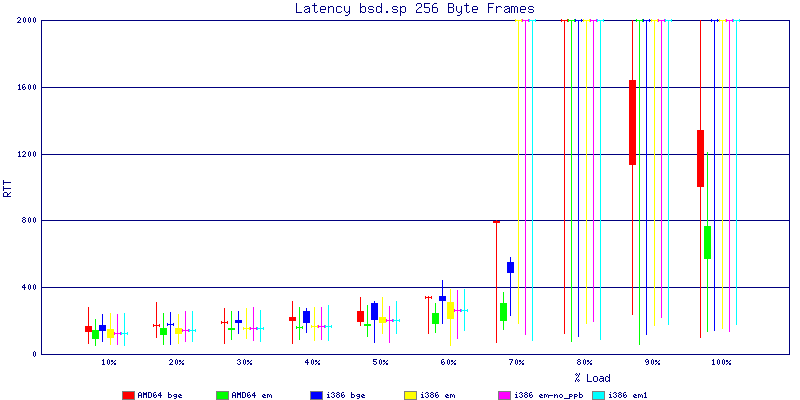
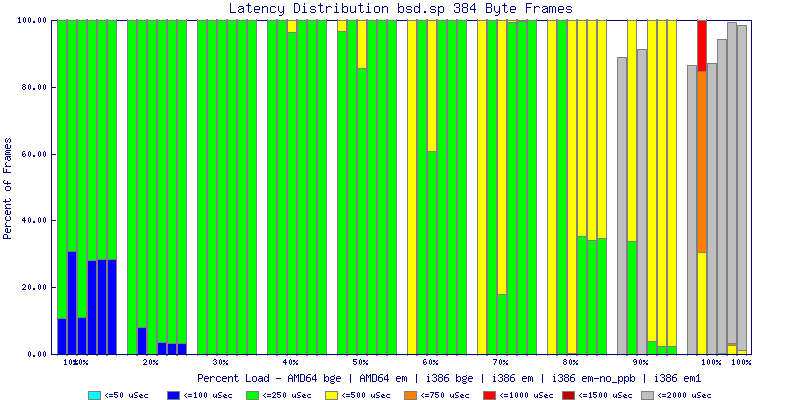
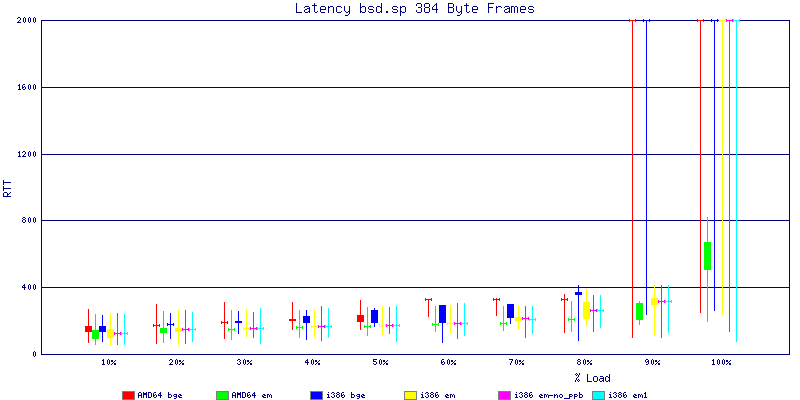
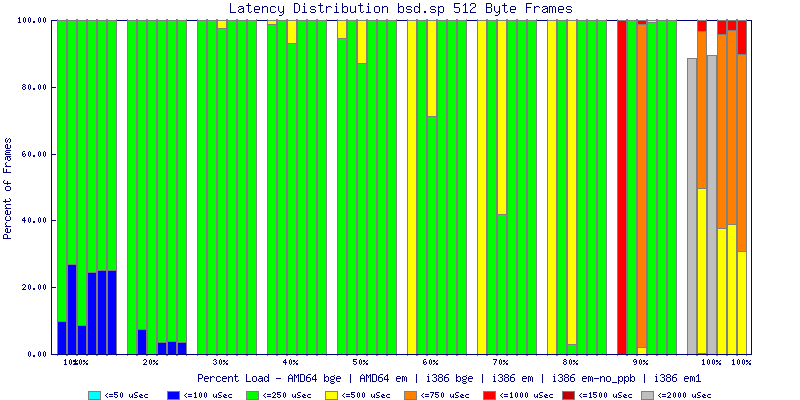
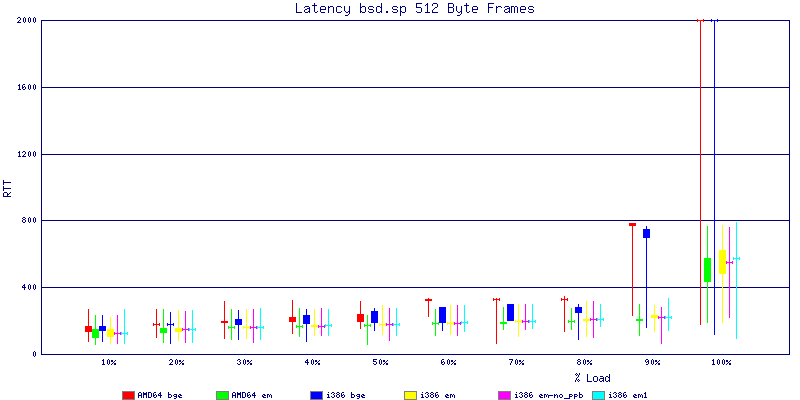
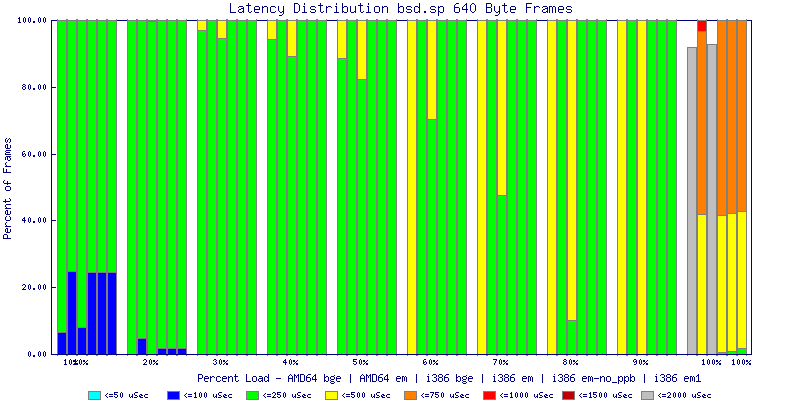
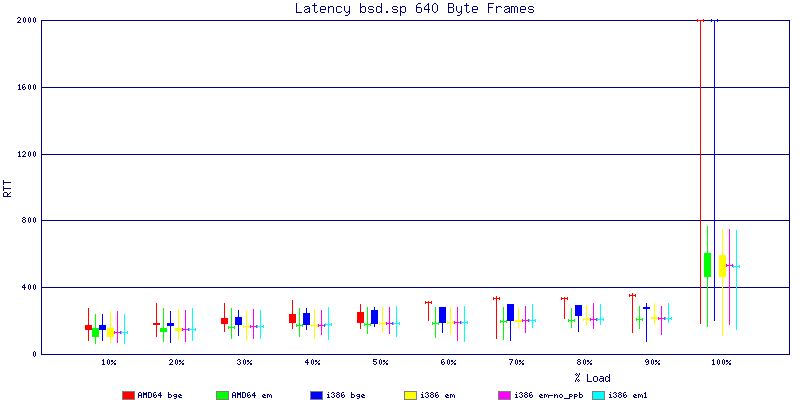
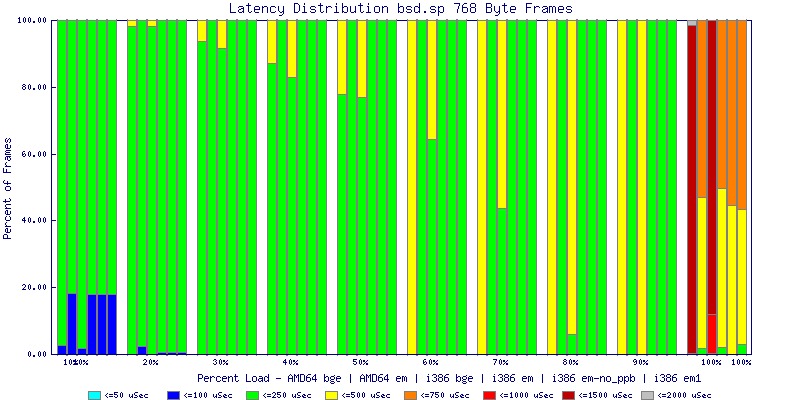
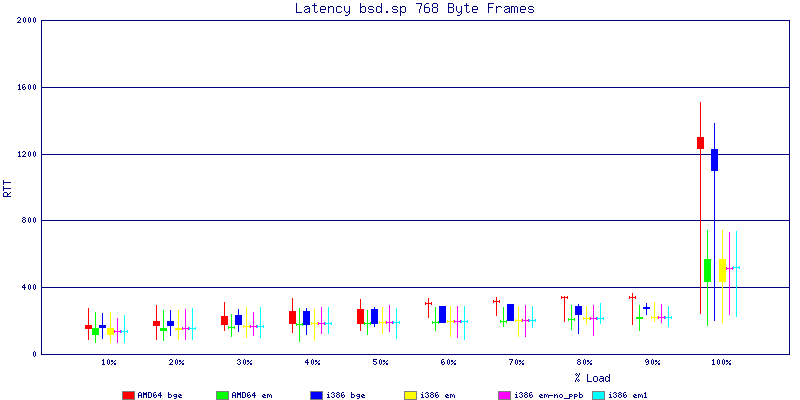
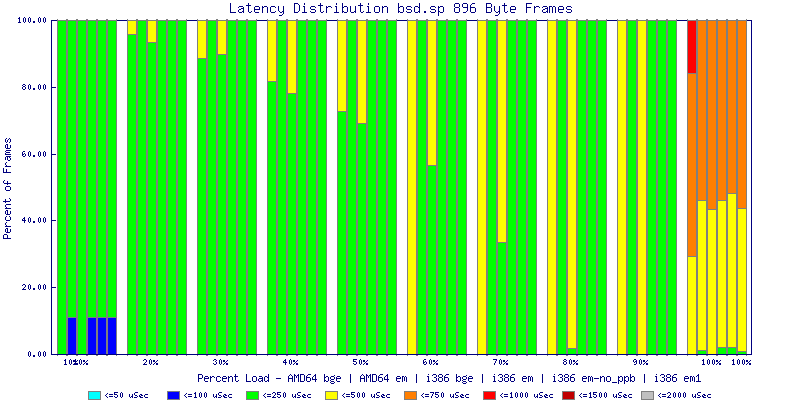
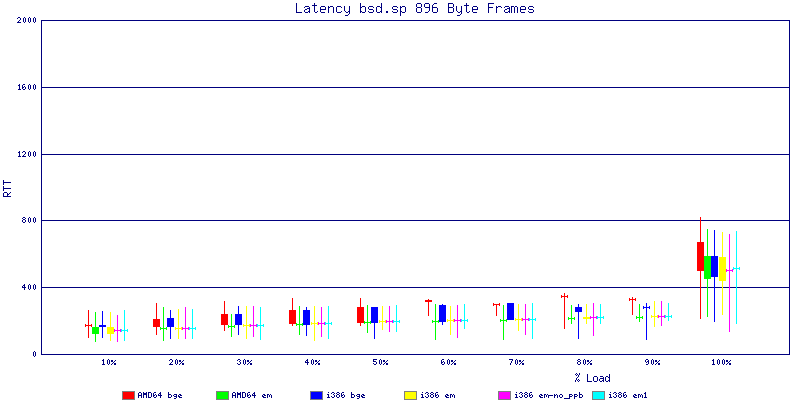
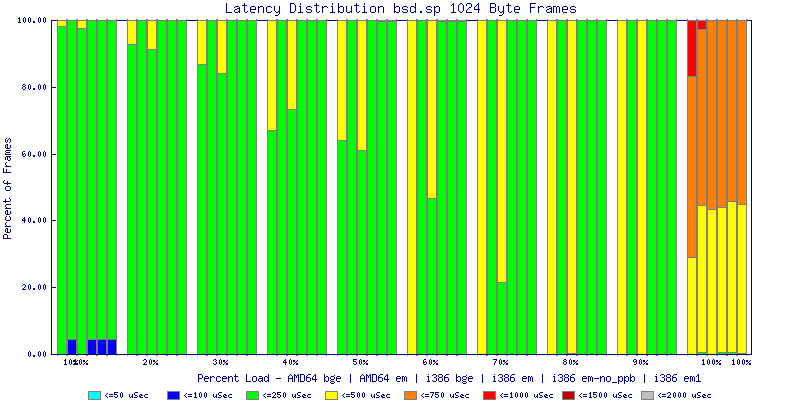
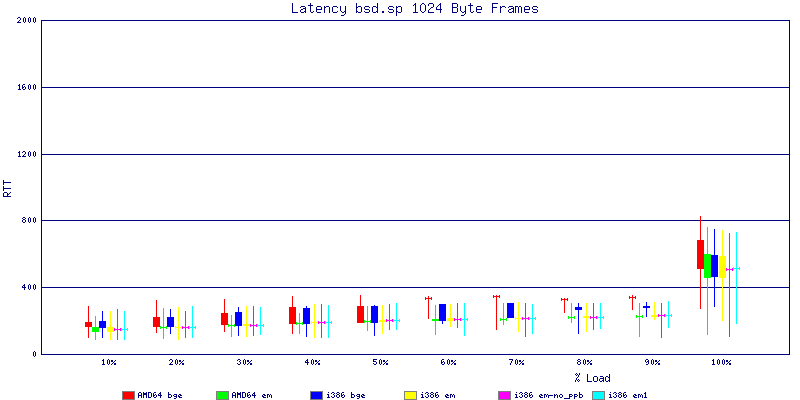
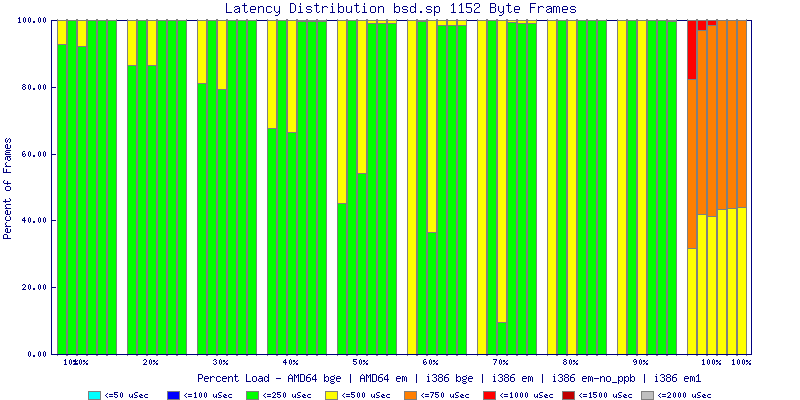
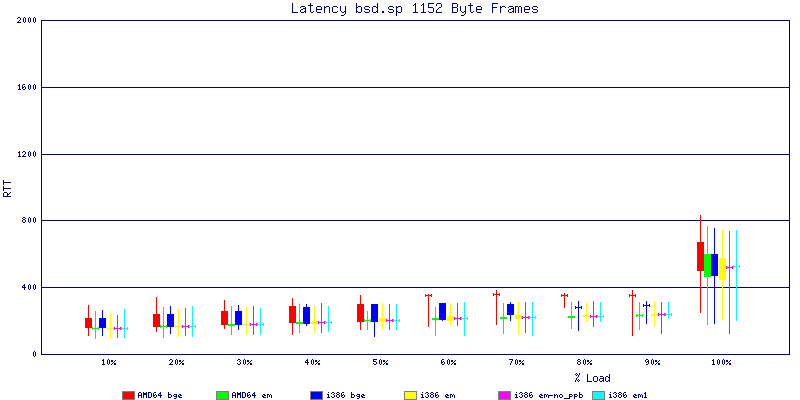
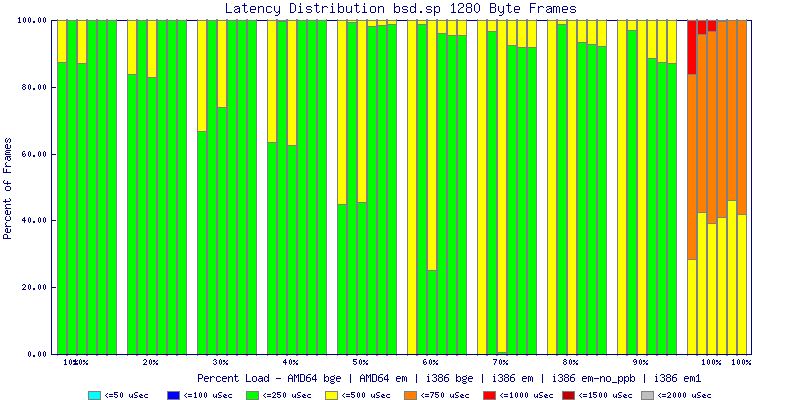
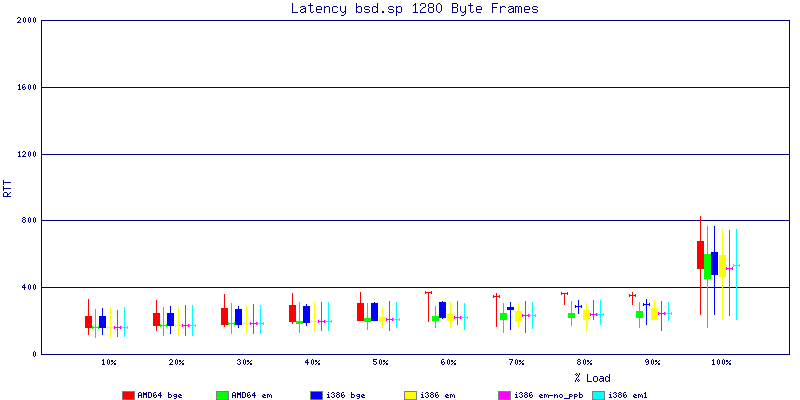
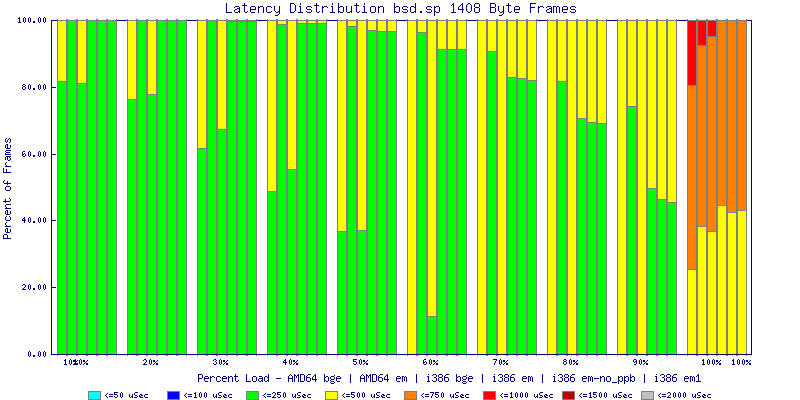
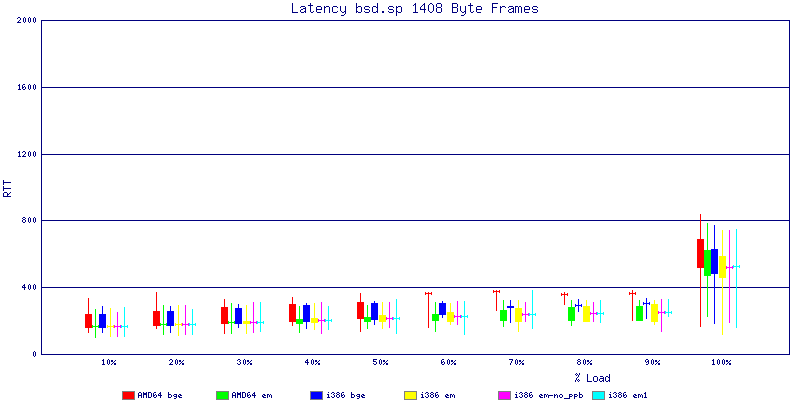
The multiprocessor results are here, but as I said, due to input errors and regular packet loss (the same number of packets every 5 seconds) the results are difficult to compare or get any useful information out of.
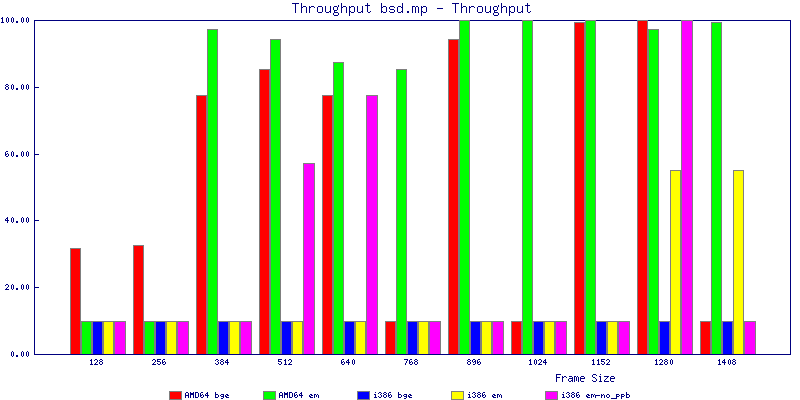
Copyright © Andrew Fresh <andrew AT afresh1.com>